Introduction to Retrieval Augmented Generation
-
Retrieval Augmented Generation (RAG) combines retrieval of information via semantic and keyword matching with Large Language Model (LLM)-based generation using provided context.
-
RAG techniques improve LLM performance by retrieving relevant external documents but face challenges with financial data complexity. These significant challenges include handling unstructured financial data, domain-specific terminology, and complex data relationships.
-
The goal of RAG is to provide accurate responses to user queries by leveraging relevant data from external sources. A key metric for RAG systems is their ability to answer questions correctly, which is essential for evaluating their effectiveness.
-
Effective RAG systems require seamless integration of retrieval and generation components. The concept of ground truth serves as the benchmark for measuring the accuracy and relevance of RAG-generated answers.
RAG Systems Overview
Retrieval Augmented Generation (RAG) systems represent a significant advancement in the field of information retrieval and large language models. By seamlessly integrating a retrieval mechanism with a generative model, RAG systems are able to provide highly accurate and contextually relevant responses to user queries. The core idea behind retrieval augmented generation is to enhance the capabilities of large language models by supplementing them with relevant documents and external knowledge, ensuring that generated answers are grounded in factual information.
A typical RAG system is composed of three main components: the retrieval module, the generative module, and the ranking module. The retrieval module is responsible for searching through vast corpora to fetch relevant documents or passages that can provide context for the user’s query. This retrieved context is then passed to the generative model, which synthesizes a coherent and informative response. Finally, the ranking module evaluates the generated responses, prioritizing those that best address the user’s needs in terms of relevance and accuracy.
RAG systems have demonstrated their effectiveness across a wide range of applications, including open domain question answering, text summarization, and dialogue generation. By leveraging both internal and external knowledge, these systems are able to tackle knowledge-intensive tasks that require up-to-date and domain-specific information. The retrieval augmented generation approach ensures that responses are not only fluent and natural but also grounded in relevant data, making RAG systems a powerful tool for anyone seeking accurate answers to complex queries.
Understanding Hybrid Search
-
A hybrid RAG system combines vector databases’ semantic similarity with knowledge graphs’ structured reasoning, leveraging structured data for superior factual correctness and trustworthiness.
-
Hybrid search methods include semantic search, keyword search, and hybrid retrieval, each with its strengths and weaknesses. Structured data from knowledge graphs complements unstructured data to improve the accuracy and reliability of hybrid RAG systems.
-
Semantic similarity searches enable finding relevant documents based on meaning, while keyword search ensures exact-term precision.
-
Hybrid search is particularly useful for knowledge-intensive tasks that require both semantic understanding and factual accuracy. Hybrid search methods can be tailored to specific business domains for more contextually relevant and accurate retrieval.
Building the Retrieval Pipeline
-
The retrieval pipeline involves ingesting and processing documents, constructing a knowledge graph, and designing the RAG system. The retrieval process is a critical step that involves querying a vector database to obtain the most relevant document chunks for a given user query.
-
Ingesting documents requires a chunking strategy to break down unstructured data into manageable chunks. External documents are divided into document chunks to facilitate effective information extraction and preserve local context within each segment.
-
Constructing a knowledge graph involves creating a structured format for representing entities and relationships. Retrieved documents and retrieved information form the foundation for generating accurate, context-aware responses in the RAG system.
-
The RAG system must be designed to integrate with the retrieval pipeline and generate accurate answers to user queries.
Ingesting and Processing Documents
-
Document chunking is essential for retrieval systems; improper chunking risks losing context and accuracy. External documents are often divided into multiple chunks to enable more granular retrieval and improve context preservation.
-
Different document types (e.g., PDF documents, financial statements) require tailored chunking strategies to preserve structure and meaning.
-
Metadata, links, and context stored with chunks improve filtering and connection of relevant data for LLM understanding. The retrieval system selects relevant chunks based on their semantic similarity to the user query. Retrieved chunks are aggregated and provided to the language model for answer generation. Retrieved contexts from the vector database serve as the basis for generating accurate responses.
-
The use of a vector database and embedding model enables efficient similarity search and retrieval of relevant document chunks. Cosine similarity is used to measure the closeness between the query and document embeddings during similarity search. Similarity search leverages high-dimensional vector representations to find the most relevant document chunks. A vector index is used to facilitate fast and scalable semantic searches over large unstructured datasets.
Constructing the Knowledge Graph
-
Knowledge graphs represent entities and relationships as graph triplets (subject, predicate, object).
-
Constructing a knowledge graph involves knowledge extraction (entity recognition, relationship extraction, coreference resolution) and knowledge improvement (KG completion, fusion).
-
Integrating internal knowledge from the language model with structured information from the knowledge graph enhances the accuracy and contextual relevance of generated answers.
-
Knowledge graphs are useful for retrieval systems as they provide a structured format for representing relevant information.
-
The knowledge graph can be used to improve retrieval accuracy and provide more accurate answers to user queries.
Designing the RAG System
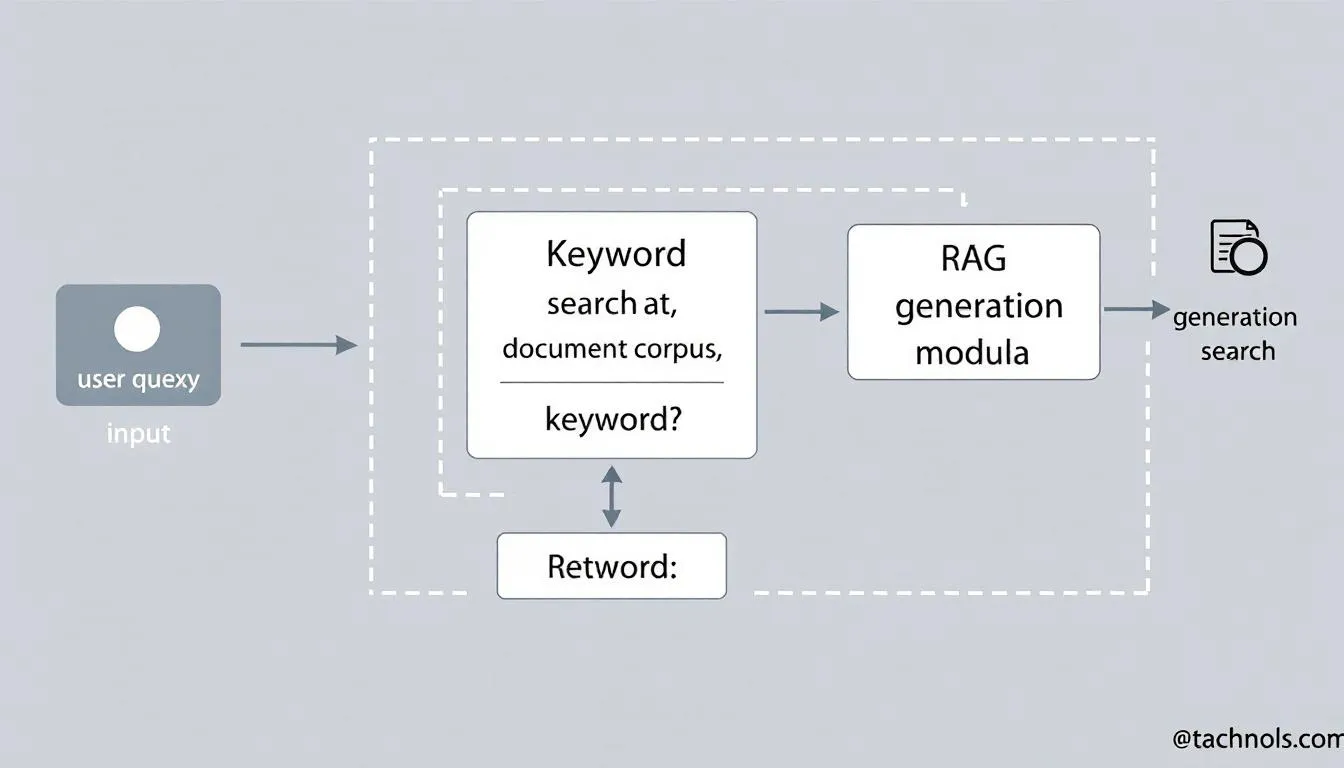
Designing an effective RAG system involves a series of strategic decisions that impact the system’s ability to retrieve and generate accurate, relevant information. One of the first considerations is the choice of retrieval algorithm. Depending on the nature of the user queries and the characteristics of the underlying corpus, different retrieval methods may be more suitable. Keyword search excels at pinpointing documents containing specific terms, making it ideal for precise queries. Semantic search, on the other hand, leverages vector databases and embedding models to identify documents that are conceptually similar to the user’s query, even if the exact keywords are not present. For many real-world applications, hybrid search offers the best of both worlds, combining the precision of keyword search with the contextual understanding of semantic search to retrieve the most relevant documents.
Once relevant documents or passages are retrieved, the generative model takes center stage. This component must be adept at synthesizing information from the retrieved context to generate a response that directly addresses the user’s query. The effectiveness of the generative model depends on its ability to interpret the retrieved context and integrate it seamlessly into the answer, ensuring both factual accuracy and contextual relevance.
The final piece of the puzzle is the ranking metric. With multiple candidate responses generated, the ranking module evaluates each one based on relevance, accuracy, and alignment with the original query. This ensures that the user receives the most pertinent and trustworthy answer possible. The choice of ranking metric can significantly influence the overall performance of the RAG system, making it a critical aspect of system design.
By carefully selecting and tuning each component—retrieval algorithm, generative model, and ranking metric—developers can build RAG systems that excel at delivering accurate, context-rich answers to a wide variety of user queries, from sustainability insights to financial data analysis.
Implementing Large Language Models
-
Large Language Models (LLMs) are essential for RAG systems as they generate answers to user queries based on the retrieved context. LLMs leverage vast amounts of training data to develop their internal knowledge and improve answer generation.
-
LLMs can be fine-tuned for specific tasks and domains to improve their performance.
-
The use of LLMs enables the generation of accurate answers to user queries, but they require relevant context to function effectively. Ensuring context relevance is crucial for the LLM to generate accurate and contextually appropriate answers.
-
The retrieval system must be designed to provide the LLM with relevant context to generate accurate answers.
Optimizing the System
-
Optimizing the RAG system involves improving retrieval accuracy, reducing latency, and increasing the efficiency of the system.
-
The use of advanced indexing techniques, such as vector search and hybrid retrieval, can improve retrieval accuracy. Reciprocal rank fusion is a method for combining the results of dense semantic retrieval and sparse lexical retrieval to improve search accuracy by fusing result sets through weighted scoring.
-
The system should be designed to handle a large volume of user queries and provide accurate answers in a timely manner. Optimizing the handling of each user query and user’s query is essential for delivering timely and accurate answers.
-
The use of distributed retrieval and parallel processing can improve the efficiency of the system.
Evaluating System Performance
-
Evaluating the performance of the RAG system involves measuring retrieval accuracy, answer generation quality, and system efficiency.
-
The use of metrics such as precision, recall, and F1-score can help evaluate the performance of the system. Evaluation also helps identify significant limitations in retrieval-based methods, especially when handling complex or nuanced information.
-
The system should be designed to provide accurate answers to user queries and retrieve relevant information from external sources.
-
The evaluation of the system should involve testing with a variety of user queries and scenarios. Additionally, the system should be tested with a broader range of document types and scenarios to ensure robust performance.
Future Directions
-
Future directions for RAG systems involve improving retrieval accuracy, increasing efficiency, and adapting to new domains and tasks.
-
The use of advanced techniques, such as transfer learning and few-shot learning, can improve the performance of LLMs. In addition, future RAG systems will increasingly focus on extracting and integrating market trends from diverse financial documents.
-
The integration of RAG systems with other AI technologies, such as computer vision and natural language processing, can enable more complex applications. Advanced retrieval and interpretation methods will also enable the generation of actionable financial insights for better decision-making.
-
The development of more advanced evaluation metrics and methodologies can help improve the performance of RAG systems.
Knowledge Intensive Tasks
-
Knowledge-intensive tasks require the retrieval of relevant information from external sources and the generation of accurate answers.
-
RAG systems are particularly useful for knowledge-intensive tasks, such as open-domain question answering and text summarization.
-
RAG systems can also be applied to retrieve and synthesize information from scientific papers, enabling advanced research and knowledge discovery.
-
The use of knowledge graphs and hybrid search can improve the performance of RAG systems on knowledge-intensive tasks.
-
The development of more advanced RAG systems can enable the automation of knowledge-intensive tasks.
Relevant Information
-
Relevant information is essential for RAG systems to generate accurate answers to user queries.
-
The retrieval system must be designed to retrieve relevant information from external sources and provide it to the LLM.
-
The use of semantic similarity searches and keyword search can help retrieve relevant information.
-
The integration of RAG systems with other AI technologies can enable the retrieval of relevant information from a variety of sources.
System Maintenance
-
System maintenance is essential to ensure the continued performance and accuracy of the RAG system.
-
The system should be designed to adapt to changes in the data and user queries.
-
The use of automated testing and evaluation can help identify issues and improve the performance of the system.
-
The development of more advanced maintenance strategies can help ensure the long-term performance of the RAG system.
Applying Knowledge Graphs
-
Applying knowledge graphs to RAG systems can improve retrieval accuracy and provide more accurate answers to user queries.
-
Knowledge graphs represent entities and relationships as graph triplets (subject, predicate, object).
-
The use of knowledge graphs can enable the retrieval of relevant information from external sources and improve the performance of the RAG system.
-
The integration of knowledge graphs with other AI technologies can enable more complex applications.
Conclusion
Building an over-engineered retrieval system using retrieval augmented generation techniques unlocks new possibilities for delivering accurate, context-aware answers to complex user queries. By combining advanced retrieval methods—such as semantic search, hybrid search, and knowledge graphs—with powerful large language models, RAG systems can efficiently surface relevant documents and generate high-quality responses grounded in external knowledge. As sustainability professionals and eco-conscious readers seek reliable information on green living, sustainable energy, and eco-friendly consumption, robust RAG systems offer a scalable solution for knowledge-intensive tasks. With ongoing advancements in retrieval accuracy, generative AI, and seamless integration of structured and unstructured data, the future of information retrieval in the sustainability domain looks brighter than ever. For more insights and updates on green technology and sustainable practices, subscribe to gogreeninsight’s newsletter and explore our featured content.
